|
本文根據2023云棲大會演講實錄整理而成,演講信息如下: 演講人:王峰 | 阿里云研究員,阿里云計算平臺事業部開源大數據平臺負責人 演講主題:開源大數據平臺3.0技術解讀
實時化與Serverless是開源大數據3.0時代的必然選擇 阿里云開源大數據平臺孵化于阿里巴巴集團內部業務。早在2009年,我們就開始采用開源 Hadoop 技術體系來服務阿里內部快速發展的電商業務。在阿里巴巴內部這套 Hadoop 技術體系,當時叫云梯一,當發展成熟后,開始上云。我們在阿里云上推出了第一款開源大數據產品 E-MapReduce,簡稱 EMR 。我們把這個定義為開源大數據平臺的第一階段,也就是1.0的時代,從此刻開始,真正跨入云原生時代。
隨著大數據技術的演進,大數據處理從離線技術架構向實時化演進,我們開始引入了Apache Flink 流計算技術。阿里巴巴對 Apache Flink 社區進行了非常大的資源投入,逐漸成為最大的用戶和社區推動者。到現在,Apache Flink 發展成為了全球范圍內流計算、實時計算的標準。同時,我們在阿里云上也推出了實時計算Flink版的實時計算云產品服務。 EMR 也在不斷地技術演進,從傳統的 Hadoop 數倉架構升級到圍繞以數據湖為核心的云原生數據湖的技術架構,因此我們把實時化和數據湖這兩個技術演進的趨勢,稱為開源大數據平臺2.0階段。 從今年開始,我們在思考下一段開源大數據平臺如何發展演進,我們做了以下幾個3.0架構的技術探索,以此更好地服務我們的客戶。 首先,我們嘗試把實時化的技術分析和數據湖的架構進行融合,我們推出了新一代的Streaming Lakehouse 架構,也就是實時化的數倉分析架構。 第二,隨著 serverless 的架構落地不斷深入,我們開始考慮什么才是云原生架構終態。今年我們將開源大數據平臺所有核心的計算、存儲組件實現了 serverless 化。 第三,現在已經全面進入AI爆發的階段,各行各業都開始使用AI的技術進行自我的革新。我們開始考慮AI的融合,希望把新的AI技術引入大數據平臺體系中,實現大數據AI一體化的能力,幫助平臺智能化運維和數據管理。 從今年開始,我們采用了新的數據分析架構、完全云原生的架構,并深度結合AI結合,開啟3.0的新架構。接下來我將選擇幾個3.0平臺中最核心的技術架構特點給大家做分享:我們做了哪些事情,取得哪些成果,以及未來會如何發展。 新一代的流式湖倉 首先介紹一下,新一代的數據分析架構——流式湖倉。我相信絕大部分用戶意識到傳統 Hadoop Hive 數倉架構的局限性以及技術發展的趨勢,都開始將傳統的Hadoop技術向著新一代的湖倉分析 Lakehouse 架構進行演進。
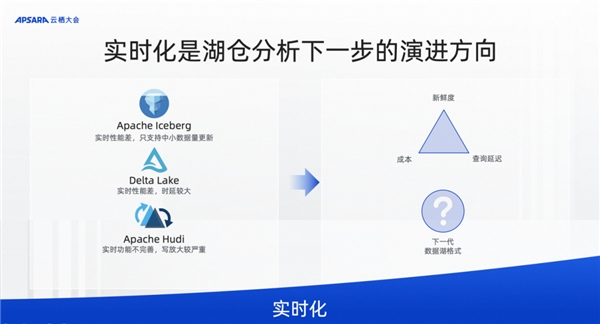
顯而易見,升級到新的 Lakehouse 數據分析架構以后有很多的優勢。比如,新Lakehouse 架構是徹底的存算分離,有更好的擴展性、靈活性。同時,新的數據湖格式也帶來了更好的實時支持以及查詢性能的提升等。Lakehouse 架構帶來的收益明顯。 但是 Lakehouse 架構是不是已經完美無缺?我覺得還沒有到這個地步。現在我們看到Lakehouse 架構在實時化方向還有進一步發展的空間,這也是眾多開源用戶在使用 Lakehouse 架構時候遇到的痛點:當數據都遷移到 Lakehouse 這個架構上,如何去更加實時化地加速數據處理管道,如何像傳統數倉一樣去實時分析 Lakehouse 中的數據。
現在的湖倉,做不到完全的實時化甚至準實時化的效果。究其原因,就是數據湖的存儲格式限制了實時化的發展。大家可以看到現在數據湖存儲格式主要是 Iceberg、Delta、Hudi 三劍客來構建的,不同的用戶和廠商會選擇不同的數據庫格式。但是Iceberg 和 Delta 是面向批處理而設計的數據湖格式,與批處理的計算引擎配合更多一些,在 Lakehouse 上實現批處理,甚至可能是比較大力度的微批處理,通過merge來更新。這個架構無法徹底實現實時化,或者在實時化的力度上也做不到特別細粒度,比如分鐘級的粒度甚至十分鐘級的粒度都是非常困難的。 Hudi 的初衷是為了解決這個問題,實現實時化的數據湖格式,提升實時更新,加速數據湖的時效性。但是,目前從架構設計和工程實現效果來看,并沒有達到預期,很多客戶在使用 Hudi 過程中也踩了很多坑,無論是系統穩定性還是系統的運維復雜度上都面臨非常大的挑戰。 其實我們可以看到,究其根源還是在湖倉架構上沒有一款面向數據實時更新或者實時分析而設計的數據湖格式。去年我們在 Flink 社區進行了技術探索,在 Flink 社區里啟動了一個新的子項目叫Flink Table Store,其目的是嘗試看PMF(市場的接受程度)。通過Flink Table Store,發現設計一款真正面向實時更新的數據湖格式還是非常有必要的,尤其是跟 Flink 這種實時流式計算引擎配合,完全能在數據湖 Lakehouse 架構上,實現實時化數據鏈路。 為了讓這個項目有更好的發展,我們今年決定把這個項目從Flink社區中獨立出來,作為一個獨立的 Apache 基金會項目去孵化,使其有一個更大的發展空間,命名為Apache Paimon。 Paimon是真正為實時更新而設計的數據湖格式,并且是完全開放的,不僅支持 Flink,也會支持 Spark、Presto、Channel、StrarRocks 等主流計算引擎。 而且由于設計時天生就是為了實時,所以性能和穩定性都是非常好,在我們典型的應用場景下,與開源 Hudi 方案相比,阿里云流式湖倉方案 Upsert 性能提升超過4倍,Scan 性能提升超過10倍。
因此,基于 Flink 和 Paimon,我們推出新一代的流式湖倉的數據分析技術,從整個數據的實時入湖到湖上實時ETL數據更新,采用一整套統一的SQL在Lakehouse來進行全鏈路的實時數據處理。由于Paimon的開放性,我們完全也可以在這個架構中引入大家用得比較多的 Spark、Presto、StrarRocks 這些開源分析引擎,也包括阿里云自研引擎MaxCompute、Hologres 都可以和 Paimon 數據進行無縫對接,實現完全開放的湖倉體系,從而整個鏈路實現完整的生態,不僅能夠實現數據全鏈路的實時流動,也能實現數據全鏈路的實時分析。這是整個3.0中數據分析架構中的演進趨勢,推動湖倉的實時化。
全面 Serverless 化 第二個,想介紹一下產品架構,我們的產品和云原生結合也邁出了重要一步,希望開源大數據平臺實現全面的 serverless 化。其實 serverless 這個技術已經探索了有好幾年,兩年前就推出了開源大數據平臺的第一款 serverless 產品—— serverless Flink,在阿里云上有非常多的客戶使用。
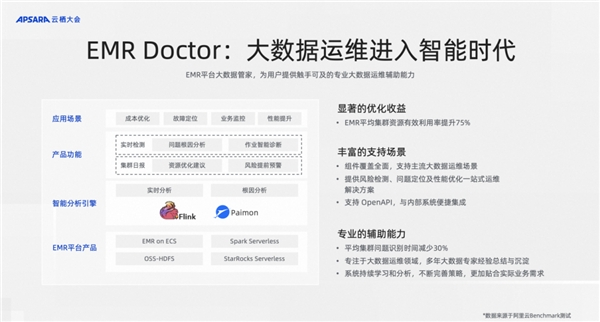
通過serverless Flink得到很多客戶的正向反饋,大家都希望使用開箱即用的開源產品。因此今年我們又推出了四款 serverless 開源大數據產品,兩款計算、兩款存儲。計算型選擇了用戶呼聲最高的 Spark 和 StarRocks,這兩款引擎推出了 EMR Serverless StrarRocks 和即將發布的 EMR Serverless Spark 兩款計算型 serverless 產品。 同時在存儲方面,我們也推出了兩款 serverless 產品,第一款是和 OSS 對象存儲團隊聯合合作推出的 OSS-HDFS ,全托管的 serverless HDFS 產品。還有一款是數據湖管理構建產品中推出了完全兼容HMS協議的全托管的 serverless 源數據管理的服務。我們通過這幾款產品的組合可以實現幾乎所有大數據場景的處理和分析。 為什么一年之內快連續推出四款 serverless 大數據產品,完全得益于我們在技術上做的沉淀。把所有對 serverless 的需求沉淀為大數據 serverless 平臺底座,這個平臺底座可以屏蔽掉阿里云各種異構硬件和資源池,提供一套完整的多租系統的管理,包括網絡隔離、資源隔離等,使得我們可以快速孵化出新的 serverless 大數據產品。 Serverless Flink 第一款產品就是 serverless Flink,它可以連通阿里云上下游的存儲,不管是數據庫、數據湖,還是數據倉庫、消息隊列,只要是阿里云上主流的存儲數據源都可以一鍵打通,提供一站式的 SQL 開發平臺,包括智能化的運維管理服務,實現開箱即用的效果。同時我們在 serverless Flink 產品中對 Flink 的核心引擎做了大量的優化,并且在阿里巴巴內部大量使用,相對于開源 Flink 引擎有兩到三倍的性能提升,所以使用serverless Flink產品不僅是方便提升開發效率,在運行效率上也會大幅節省成本。 今年上半年新推出來另外一個新的 serverless 數據產品就是 serverless StarRocks,主要是解決實時交互式分析 OLAP 場景用戶的需求,現在 OLAP 或者實時分析也是熱點。我們評估下來目前在開源界內最主流的或者最優秀的 OLAP 引擎是 StarRocks,所以我們選擇了 StarRocks 在 EMR 上開通了第一款 serverless OLAP 產品,因為StarRocks 是一個完全向量化的 C++引擎,所以性能非常優秀,支持數萬的并發。 Serverless StarRocks 同時在最新版本的 StarRocks 中其實也支持存算分離的架構,結合整個產品的云原生能力推出了 Virtual Warehouse 的功能可以兼顧彈性和用戶業務之間的隔離性。有了這個存算分離之后,可以將 StarRocks 和數據湖進行打通。流式湖倉會在湖上沉淀出非常多實時更新的數據,這個時候利用 serverless StarRocks 就可以去查詢湖上的實時更新數據,即時查詢得到一個很好的湖倉一體的效果,稱之為大湖小倉的布局。 Serverless Spark 今年還有一款重磅級產品的 serverless 產品就是 serverless Spark。相信 Spark 在開源大數據體系中用得最多的計算引擎,也是現在 EMR 中看到最重要的一款計算引擎。 最近幾年,我們不斷聽到用戶的呼聲,希望有一款真正全托管免運維 serverless 的Spark 產品,能夠幫助客戶減輕運維的負擔,提升開發的效率,甚至提升運行的效率。因此今年在全面 serverless 化的目標下投入了非常大的資源,做出了 serverless Spark 產品,很快將進行公測和商業化。 Serverless Spark 產品其實是集成了前面兩款 Flink 和 StarRocks Serverless 產品的優勢,一站式開發和智能化運維都可以實現開箱即用,按量付費完全彈性,包括和數據湖的打通等等。此外我們在Serverless Spark里面還內置了基于 Celeborn 做的一個Serverless 數據服務,這樣就可以免除對本地盤的依賴,完全實現整個數據計算的Serverless 化。 Serverless HDFS(OSS-HDFS) 剛才講了幾款 serverless 計算的產品,接下來還有一款產品是非常重要,就是存儲的serverless 產品。我們叫 serverless HDFS,官方產品名字是 OSS-HDFS,這是和 OSS 團隊一起共建出來的產品形態。 大家都知道 HDFS 已經在大數據業界被大家認為是一款事實標準的文件系統協議,隨著越來越多用戶把數據搬到數據湖上,同時希望繼續使用HDFS協議來訪問數據湖上的數據,這樣計算都是兼容的。 因此,我們把 OSS 的數據也可以包裝成一個看上去像無限大的云 HDFS,這樣就可以滿足很多用戶的需求。所以今年聯合 OSS 團隊發布了 OSS-HDFS 的 serverless 文件系統,完全兼容 HDFS 。有了這個后,很多用戶就不必自己去維護本地HDFS集群,免除了運維的復雜度,而且完全按量付費,有非常好的彈性,結合我們計算的原倉數據可以做智能的數據分析、冷熱數據分層,幫助用戶更好地降本增效。 剛才也講了 serverless 是開源大數據3.0中在云原生架構上的進展,未來在 serverless端上會繼續推出更多的產品。 更智能的開源大數據 當前 AI 全面爆發,阿里云開源大數據平臺也將 AI 技術引入大數據平臺體系中,幫助我們做智能化平臺運維或者數據管理等。今年,我們升級了智能化運維工具 EMR Doctor、Flink Advisor,并已廣泛應用于客戶和阿里云內部平臺運維,平均集群問題識別時間減少30%,集群資源有效利用率提升75%。 大家知道在 EMR 產品中運維是非常有挑戰性的事情,因為 EMR 上有非常多的組件,Hadoop、Hive、Kafka、Spark、Flink、Presto 等,一旦系統出現問題怎么快速地定位問題,是一個非常讓用戶頭疼的事情。甚至有時候即使沒有出現問題,用戶也希望對整個集群的資源利用率、存儲效率進行提升。 之前完全都是靠人肉經驗的去沉淀。前些年,我們也投入了很多的工程師幫助客戶人肉解決這些問題,但近些年我們都把這些經驗和知識沉淀成AI中的知識庫、規則庫,再結合一些傳統機器學習算法和數據分析的方法,進行智能化定位問題,給用戶建議,讓用戶優化集群,解決問題。
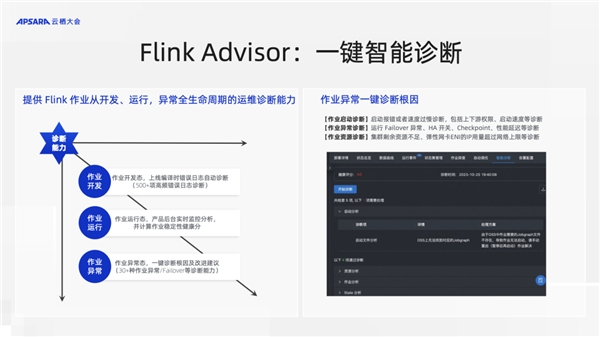
此外。在Flink產品中也做了大量的實踐,推出了智能診斷的服務 Flink Advisor。可以在開發運維的全生命周期中幫助用戶定位,你的任務為什么出錯了,出錯在哪里,怎么修正、改進。即使在你的任務沒有問題的時候也依然對你的任務做健康檢測,判斷潛在可能出現的風險,類似于健康分這種能力,幫助用戶防范于未然,給用戶一些智能化的提議,讓用戶去優化任務。其實這背后都是采用了大數據AI相結合的分析技術做到的。
最后提到AI,我覺得有一個詞首先進入開發者的視線,就是向量檢索。在AI時代,所有非結構化的數據都可以用向量來表示,關于向量檢索的技術也如雨后春筍般層出不窮。目前業界各種開源向量檢索技術,經過我們評估后認為 Milvus 這個技術是目前最流行的,也是用戶需求量最大的向量檢索技術,因此開源大數據平臺也將推出全托管 serverless 向量檢索服務,基于開源的Milvus生態、阿里云的PAI機器學習平臺和各種大模型組成完整的大數據AI一體化的技術解決方案去服務在AI場景下對向量檢索有需求的客戶。 以上就是關于開源大數據平臺3.0的核心技術架構以及技術發展趨勢的分享。我們希望這些新技術能夠在產品中落地,服務客戶,得到客戶的反饋。謝謝大家的聆聽。 |
免責聲明:本網站內容由網友自行在頁面發布,上傳者應自行負責所上傳內容涉及的法律責任,本網站對內容真實性、版權等概不負責,亦不承擔任何法律責任。其原創性以及文中陳述文字和內容未經本站證實,對本文以及其中全部或者部分內容、文字的真實性、完整性、及時性本站不作任何保證或承諾,并請自行核實相關內容。本站不承擔此類作品侵權行為的直接責任及連帶責任。如若本網有任何內容侵犯您的權益,請及時聯系我們,本站將會在24小時內處理完畢。