|
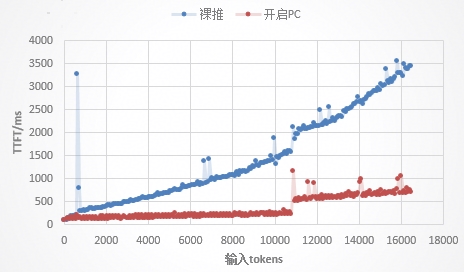
AI產業已從“追求模型能力極限”轉向“追求推理體驗最優化”,推理體驗決定用戶與AI的交互質感。當前推理應用快速發展,Token調用量爆發式增長,推理遇到“推不動、推得慢、推得貴”三大瓶頸,成為產業規模化發展的攔路虎。在有限算力下,長序列輸入導致首Token時延(TTFT)增加,甚至超長序列超出模型上下文窗口限制;隨著并發數增加,推理吞吐開始下降,任務頻繁卡頓;歷史對話和行業知識的重復調用造成算力浪費,加大推理成本。如何優化推理效率,是AI產業突破發展瓶頸的關鍵。 算力的有效利用對AI推理性能和成本優化發揮著至關重要的作用,是企業核心競爭力。算力平臺需適配多元存儲、Kubernetes集群及推理框架,但硬件生態碎片化、資源分配僵化、調度缺乏AI任務感知、運維可觀性不足等技術兼容難題,正嚴重制約推理應用發展。 近日,華為數據存儲與「DaoCloud 道客」聯合推出了AI推理加速聯合解決方案。該方案融合了華為UCM(Unified Cache Manager)推理記憶數據管理技術和道客d.run算力調度平臺,圍繞大模型歷史數據,實現KV Cache數據池化管理,以資源的精細化管理和智能調度提升算力利用率,為AI推理加速提供全方位技術支撐。 道客d.run算力調度平臺可支持算力與顯存資源的細粒度切分及池化,通過多種調度策略實現算力資源的最大化利用。調度器具備拓撲感知能力,可優化任務在xPU間的通信效率,保障AI任務穩定低耗運行。平臺提供企業級運維支持,提供多租戶隔離、資源配額管理、完整的監控告警及計費計量等功能,滿足企業級使用與運維需求。同時具備多元生態兼容性,適配NVIDIA、華為昇騰、寒武紀等多種品牌AI算力,支持TensorFlow等主流AI框架,借助Kubernetes的CSI無縫對接華為OceanStor AI存儲,簡化管理并為AI任務數據讀寫提供穩定支撐。 華為UCM是以KV Cache為核心,構建多級緩存空間的分層管理與智能流動機制,實現數據在高性能緩存HBM、內存DRAM和外置OceanStor A系列存儲的分級緩存和查詢,確保推理記憶知識全量保存。并且,UCM還融合多項創新加速算法:自適應全局Prefix Cache支持公共前綴、歷史對話和RAG知識塊多種拼接組合場景的復用,通過以查代算,最大程度改善TTFT;全流程稀疏加速算法提供Prefill階段的超長KV分片卸載和增量稀疏,以及Decode階段的動態稀疏,提升長序列推理吞吐。 在Qwen3-32B模型上,測試問答助手場景,開啟Prefix Cache和RAG Chunk功能。測試數據表明,首Token時延降低約55%,且隨著序列長度越長,TTFT降低效果越明顯,通過“以查代算”的方式,避免了大量歷史對話信息的重復計算。
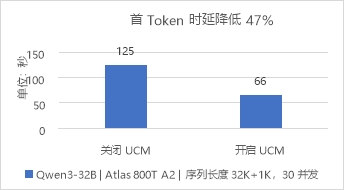
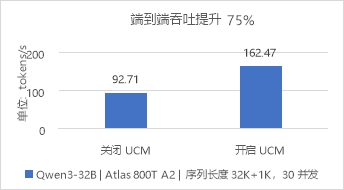
圖1 問答助手場景對比開關UCM的TTFT 測試長文檔推理場景,設定序列長度輸入32K+輸出1K,開啟Chunk Prefill和GSA稀疏化功能。測試數據表明,在并發數為30時,TTFT最大降低47%,端到端吞吐最大提升75%。
圖2 長文檔推理場景對比開關UCM的TTFT
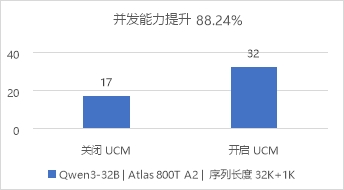
圖3 長文檔推理場景對比開關UCM的E2E吞吐 關閉UCM,當并發數超17時,請求開始排隊;開啟UCM,當并發數超32時,請求開始排隊。在以上情況下,開啟UCM對比關閉UCM場景,并發能力提升88.24%。
圖4 長文檔推理場景對比開關UCM的并發能力 目前,該方案正在電力、金融等行業試點。未來,雙方將持續深化技術合作,推動技術迭代與行業適配,助力AI技術在更多行業的落地應用。 |
免責聲明:本網站內容由網友自行在頁面發布,上傳者應自行負責所上傳內容涉及的法律責任,本網站對內容真實性、版權等概不負責,亦不承擔任何法律責任。其原創性以及文中陳述文字和內容未經本站證實,對本文以及其中全部或者部分內容、文字的真實性、完整性、及時性本站不作任何保證或承諾,并請自行核實相關內容。本站不承擔此類作品侵權行為的直接責任及連帶責任。如若本網有任何內容侵犯您的權益,請及時聯系我們,本站將會在24小時內處理完畢。